Executive Summary
Geospatial systems are no longer peripheral tools; they underpin critical infrastructure, national security functions, and capital-intensive operations across government and industry. They support logistics, infrastructure management, environmental compliance, security operations, and strategic planning across government and industry. Yet many organizations rely on externally managed platforms for the storage, processing, and delivery of spatial intelligence.
This post discusses the concept of geospatial sovereignty, a governance and risk management discipline concerned with the degree to which an organization retains control over its geospatial data, infrastructure, and operational continuity.
As regulatory requirements expand, vendor ecosystems consolidate, positioning infrastructure faces disruption, and sovereign cloud models gain traction, executive teams must understand where they sit on the spectrum between dependency and control. The objective is informed, intentional architecture grounded in clear visibility into operational risk and long-term optionality.
Perception of Operational Control
For more than a decade, convenience has shaped enterprise technology decisions. Cloud-hosted platforms reduced infrastructure burdens. Subscription licensing simplified procurement. Managed services shifted operational responsibility outward. For many organizations, these shifts accelerated deployment and reduced internal complexity. But in the domain of geospatial operations, a different question is emerging: Who actually controls the systems that underpin your spatial intelligence?
Consider a composite scenario drawn from observable trends. A logistics provider experiences degraded positioning data during a regional GPS disruption and discovers that routing intelligence depends on upstream signals it does not control. A cloud vendor modifies pricing tiers or usage thresholds, quietly altering long-term cost projections embedded in multi‑year operating plans. A regulatory audit raises questions about data residency and physical storage location, forcing leadership to answer questions they assumed were settled at contract signature. A mission‑critical geospatial workflow is interrupted by an upstream service outage, revealing how tightly coupled internal processes have become to external infrastructure.
In each case, the organization technically “owns” its mission and its data. Yet operational continuity depends on infrastructure, policy decisions, and technical roadmaps defined elsewhere. This is not a critique of cloud providers; many are reliable, professionally managed, and appropriate for a wide range of workloads. The issue is structural. Control of infrastructure, data, and operational continuity is not the same as platform access. When those elements diverge, organizations may discover that their geospatial capabilities are more dependent than leadership intended.
From Data Sovereignty to Geospatial Sovereignty
The concept of sovereignty in digital systems is not new. Data sovereignty is commonly defined as the principle that data are subject to the laws and governance structures of the jurisdiction in which they are collected or stored.
It is important to distinguish related but separate concepts. Data residency refers to the physical location where data are stored. Data localization refers to legal requirements that certain categories of data remain within specific geographic boundaries. Data sovereignty concerns the legal authority governing that data and the jurisdiction whose laws apply. These distinctions are discussed in detail by enterprise security and cloud governance analysts (CIO, 2026).
Increasingly, major technology publications are also examining “sovereign cloud” and “geopatriation” trends, where governments and enterprises seek to re-anchor sensitive workloads within controlled jurisdictions. These discussions reinforce that sovereignty is not theoretical. It is shaping procurement, cloud architecture, and national digital strategies.
Geospatial sovereignty extends this conversation beyond legal jurisdiction. It asks whether an organization retains meaningful authority over how its spatial infrastructure is architected and governed, whether operations can continue during vendor, network, or geopolitical disruption, how systems are updated and configured, how spatial data integrates with broader enterprise platforms, and where critical skills and knowledge reside.
In this context, sovereignty is operational. It concerns who can make consequential decisions about the systems that support mission execution.
Why This Issue Is Emerging Now
Several converging pressures are elevating geospatial sovereignty from a technical concern to an executive one.
1. Geospatial Is Foundational
Spatial data now informs asset management, utilities maintenance, supply chain routing, environmental monitoring, agriculture, mining, emergency response, and national security operations. As geospatial becomes core to operations, its governance becomes a strategic concern. National Academies research has repeatedly emphasized that geospatial information infrastructure is critical to modern governance and infrastructure management (National Academies of Sciences, Engineering, and Medicine, n.d.).
2. Regulatory and Compliance Demands Are Expanding
Globally, more than one hundred privacy and data governance laws now affect how organizations collect, process, and store data. These include GDPR in the European Union and numerous national and state-level frameworks.
As data governance regimes expand, spatial datasets, which are often rich with location intelligence tied to individuals, infrastructure, or sensitive assets, fall under increasing scrutiny. European discussions around building digital sovereignty through authoritative geodata emphasize that trusted, nationally governed datasets are foundational to public policy, security, and economic competitiveness (GIM International, 2026). The implication for enterprises is clear that geospatial data is no longer merely operational. It is policy-relevant and potentially regulated. Governance expectations are rising accordingly.
Commercial perspectives are echoing this shift. Industry commentary aimed at enterprise operators has begun to frame sovereign geospatial data as a competitive and operational necessity rather than a compliance afterthought. Discussions emphasize that organizations dependent on third-party platforms for core spatial intelligence may struggle to preserve data lineage, portability, and strategic control as markets evolve (Nimbo, 2025). The argument is not ideological; it is pragmatic. When spatial data informs capital allocation, logistics optimization, and asset performance, control over that data becomes economically material.
3. Vendor Ecosystems Are Consolidating
The technology industry continues to experience consolidation through mergers and acquisitions. Platform acquisition can alter licensing terms, support models, product roadmaps, and pricing structures.
Organizations that rely exclusively on proprietary ecosystems may find their long-term cost models and integration assumptions shifting unexpectedly. Industry commentary has begun to frame geospatial sovereignty as requiring both legal alignment and architectural foresight, which highlights that compliance without architectural control can still leave organizations strategically exposed (CARTO, 2026).
In other words, sovereignty is not solved by contract language alone. It must be reflected in system design.
4. Strategic Uncertainty Is Increasing
Positioning, Navigation, and Timing (PNT) infrastructure such as the Global Positioning System (GPS) is globally relied upon and operated by national governments (U.S. Space Force, 2023). Disruptions, whether technical, environmental, or geopolitical, demonstrate that foundational spatial services are not immune to systemic risk.
Recent analysis from Australia’s spatial industry has highlighted both the economic potential and systemic vulnerability of national PNT infrastructure. Commentary in Spatial Source has warned that while modern economies are deeply dependent on satellite-based positioning, they often lack redundancy and assurance frameworks to mitigate disruption (Spatial Source, 2026a).
Further, discussion of “navwar,” or navigation warfare, underscores that PNT denial and degradation are no longer theoretical military edge cases but active considerations in contested environments (Spatial Source, 2026b). Even outside conflict scenarios, signal interference, spoofing, and systemic outages pose measurable operational risk.
In response, governments are investing in resilience and sovereign capability. Frontiersi’s launch of Australia’s first dedicated PNT Labs reflects a recognition that positioning infrastructure requires independent testing, validation, and assurance capacity (Spatial Source, 2025). Similarly, Canada’s evolving Defence Industrial Strategy explicitly acknowledges the strategic importance of domestic geospatial capability within national security and industrial planning (GoGeomatics Canada, 2026).
These developments signal a broader shift. When governments treat geospatial and PNT systems as strategic assets requiring sovereign capability, commercial enterprises should take note. If national infrastructure planners view spatial systems through a sovereignty lens, enterprises whose operations depend on those systems must evaluate their own dependency assumptions.
At the same time, analysts are emphasizing that data provenance and trust are becoming central to reliable forecasting, AI modeling, and decision support. Without clear lineage and governance, spatial analytics risk becoming less defensible and less auditable (Ready Signal, 2026).
When spatial infrastructure becomes integral to mission execution, resilience and traceability are no longer purely technical considerations. They become executive concerns tied to continuity, liability, competitive positioning, and public trust.
Costs of Dependency
Dependency is rarely visible when systems function as expected. It becomes visible when change is required. Organizations may discover that data export is limited or constrained by proprietary formats, that migration costs are materially higher than anticipated, or that integration depth is bounded by vendor APIs rather than internal design choices. Custom workflows may be constrained by externally managed roadmaps, and over time internal skills may atrophy because expertise resides primarily with the platform provider rather than within the enterprise.
These costs are often architectural rather than purely financial. They shape how quickly an organization can pivot, how confidently it can integrate acquisitions, and how effectively it can respond to regulatory change. Over time, optimizing for short-term convenience can reduce long-term flexibility. That trade-off may be acceptable for commoditized functions. It is less acceptable when spatial intelligence underpins strategic decision-making.
Sovereignty as Institutional Capability
At its most practical level, geospatial sovereignty is about institutional capability. It asks whether the organization possesses the internal knowledge required to operate and evolve its spatial systems, whether it can transition platforms without losing intellectual capital, whether its most critical spatial workflows are portable, and whether leadership has explicitly defined which components must remain under direct control.
Sovereignty exists on a spectrum, ranging from fully vendor-managed SaaS environments where infrastructure and architectural direction are externally controlled to fully self-managed systems governed internally. Most organizations operate somewhere between these poles. The leadership challenge is to ensure that dependency is intentional, understood, and aligned with mission risk tolerance. Where dependency is acceptable, it should be consciously accepted; where it is not, architectural adjustments should follow.
The Architecture Question
When organizations examine geospatial sovereignty seriously, the discussion shifts from tools to architecture. Questions emerge that are fundamentally architectural in nature. Which datasets are mission-critical versus supportive? Which workflows must remain operational during network disruption? Where does regulatory exposure exist? Which integrations define competitive advantage? How portable are spatial assets across platforms and vendors?
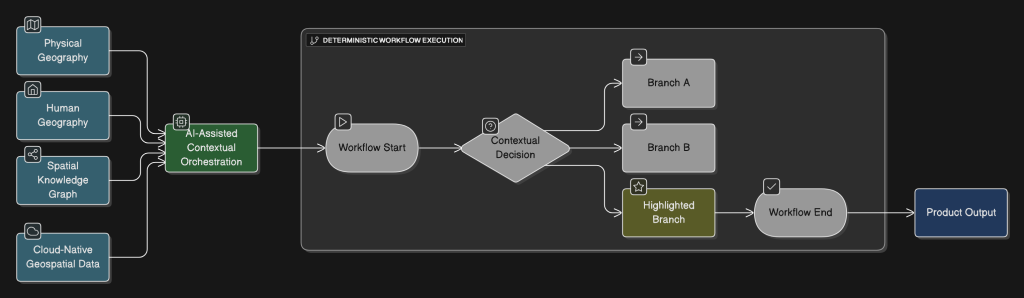
Answering these questions requires cross-functional engagement across technology, operations, legal, compliance, and executive leadership. The conversation moves beyond tool comparison and into enterprise design. Sovereignty is ultimately a governance and architecture exercise intersecting risk management, operational resilience, and long-term strategy.
Seeking Guidance
As geospatial systems become more deeply integrated with enterprise operations, governance cannot remain purely technical. Executive leadership increasingly needs visibility into structural dependencies, long-term total cost trajectories, regulatory exposure, continuity planning assumptions, and the sustainability of internal talent.
Organizations that evaluate sovereignty proactively retain optionality. Those that defer the conversation may discover constraints only when disruption forces action. In that moment, architectural flexibility is no longer a strategic advantage; it becomes an emergency requirement.
The role of trusted advisors in this context is not to prescribe universal solutions or advocate a single technology stack. It is to help organizations map existing dependencies, clarify strategic priorities, assess architectural alternatives, and align technology decisions with mission risk tolerance. Sovereignty decisions should reflect leadership intent rather than historical inertia.
For organizations navigating this terrain, the challenge is rarely theoretical. It is practical, architectural, and often constrained by legacy decisions. Experienced advisory support can help leadership teams translate sovereignty from an abstract principle into an actionable roadmap. That work begins with disciplined assessment, grounded risk analysis, and a clear understanding of how geospatial capabilities align with mission priorities.
A Conversation Worth Having
This discussion does not require immediate platform replacement or imply that current systems are deficient. It begins with assessment. Who controls your geospatial infrastructure? Where are your true dependencies? Which elements are strategic, and which are commoditized?
As spatial intelligence becomes central to both public and private sector operations, these questions move from theoretical to structural. They shape procurement strategy, workforce planning, compliance posture, and long-term competitiveness.
In subsequent posts, we will examine architectural models, hybrid approaches, and the role of open-source ecosystems in enabling greater geospatial independence without sacrificing innovation. We will also explore practical assessment frameworks that allow leadership teams to quantify dependency instead of debating it abstractly.
For now, the imperative is straightforward: understand your position on the sovereignty spectrum before external events force the issue. In an era of increasing complexity, control means ensuring that the systems most critical to your mission remain aligned with strategic intent.
References
CARTO. (2026, Jan 15). Geospatial sovereignty requires law and architecture. https://carto.com/blog/geospatial-sovereignty-why-it-requires-both-law-and-architecture
CIO. (2026, Feb 13). Geopatriation and sovereign cloud: How data returns to its origin. https://www.cio.com/article/4131458/geopatriacion-and-sovereign-cloud-how-data-returns-to-its-origin.html
GIM International. (2026, Feb 25). Building digital sovereignty through authoritative European geodata. https://www.gim-international.com/content/news/building-digital-sovereignty-through-authoritative-european-geodata
GoGeomatics Canada. (2026, Feb 18). What Canada’s defence industrial strategy really means for geospatial. https://gogeomatics.ca/what-canadas-defence-industrial-strategy-really-means-for-geospatial/
National Academies of Sciences, Engineering, and Medicine. (n.d.). Geospatial information infrastructure and governance. https://www.nationalacademies.org/read/28857/chapter/10
Nimbo. (2025, Dec 2). Sovereign geospatial data. https://nimbo.earth/stories/sovereign-geospatial-data/
Ready Signal. (2026, Feb 19). Data sovereignty, provenance, and trustworthy forecasts. https://www.readysignal.com/blog/data-sovereignty-provenance-trustworthy-forecasts-2026
Spatial Source. (2026, Feb 20). Australian PNT: Lots of potential, lots of danger. https://www.spatialsource.com.au/australian-pnt-lots-of-potential-lots-of-danger/
Spatial Source. (2026, Feb 10). PNT assurance in the age of navwar. https://www.spatialsource.com.au/pnt-assurance-in-the-age-of-navwar/
Spatial Source. (2025, Feb 26). Frontiersi launches Australia’s first PNT labs. https://www.spatialsource.com.au/frontiersi-launches-australias-first-pnt-labs/
U.S. Space Force. (n.d.). Global Positioning System (GPS). https://www.spaceforce.mil/About-Us/Fact-Sheets/Article/2197765/global-positioning-system/
Header image: Mhsheikholeslami, CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0, via Wikimedia Commons