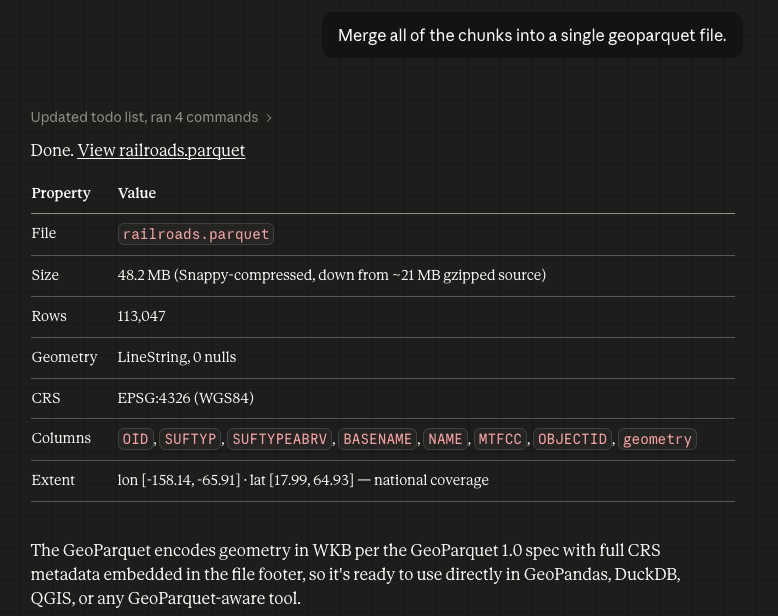
153 feeds monitored. Published May 1, 2026.
Executive Summary
Two themes defined this week, and they reinforce each other in ways that deserve executive attention. The first is vendor consolidation. VertiGIS’s £87 million acquisition of 1Spatial marks the largest geospatial M&A event in recent months, combining enterprise data quality with location intelligence in a deal explicitly framed around the next wave of AI-powered geospatial networks. The second is the accelerating reconceptualization of geospatial from a mapping function to decision infrastructure. GoGeomatics’s interview with Nadine Alameh ahead of GeoIgnite 2026 and a Reimagining Geospatial post on “Earth models” both articulate the same thesis from different angles: the industry is moving from maps to autonomous decision loops, with geospatial foundation models as the enabling architecture.
These two threads, consolidation around data quality and the rise of AI decision infrastructure, are not coincidental. As the stakes of spatial AI outputs grow, the demand for accurate, authoritative, well-governed base data grows with it. The VertiGIS/1Spatial deal is, in part, a bet on exactly that premise.
Alongside these, FedGeoDay 2026 surfaced a distinct and important development: the U.S. federal government is treating geospatial data preservation as a national security priority, not merely an archival task. Combined with Bentley Systems achieving FedRAMP authorization for its infrastructure digital twin platforms, the government market is quietly but consistently hardening its geospatial data infrastructure. Leaders should watch this track closely because it is where procurement follows strategic intent.
Major Market Signals
Enterprise Consolidation Accelerates Around Data Quality and Location Intelligence
The VertiGIS acquisition of 1Spatial, a £87 million take-private deal announced Thursday, is the clearest indication yet that the upper tier of enterprise geospatial is consolidating around the convergence of data quality, governance, and AI-ready infrastructure. VertiGIS, best known for its GIS application platforms built on Esri and open-source stacks, is acquiring 1Spatial’s global data quality and management business. The combined entity positions itself to serve the data quality demands that AI-driven geospatial workflows expose at scale. For executives, the implication is straightforward: when AI systems ingest spatial data for automated decisions, bad data quality has operational consequences, not just analytical ones. The deal suggests that the market recognizes this and that vendors are racing to own the quality layer before their customers demand it as a commodity.
Geospatial Reframes From Mapping to Decision Infrastructure
Two independent posts this week articulate what may become the defining strategic narrative of 2026: geospatial is ceasing to be a visualization and analysis tool and becoming the substrate for autonomous decision-making. Nadine Alameh’s GeoIgnite 2026 preview interview frames natural language interfaces and GeoAI as enabling “decision loops,” or systems that act on spatial intelligence rather than merely displaying it. At the same time, Reimagining Geospatial published a structural analysis of “Earth models” that asks whether the industry will produce one comprehensive geospatial foundation model or a proliferation of vertical-specific models. These are not theoretical discussions. They define the architecture of geospatial AI investment for the next three years. The convergence of two independent voices on this idea in a single week suggests the market’s mental model is shifting.
U.S. Federal Geospatial: From Access to Resilience
FedGeoDay 2026, held at the U.S. Census Bureau in Suitland, Maryland, drew coverage from two independent observers this week. Both noted a pronounced shift in the event’s thematic focus toward data preservation and federal data stewardship. The opening keynote by Denice Ross anchored a program explicitly oriented around what happens to geospatial data assets when agencies are restructured or defunded. Separately, Bentley Systems announced FedRAMP authorization for ProjectWise and OpenGround, enabling federal agencies to deploy its infrastructure digital twin environment in compliant cloud settings. Taken together, these developments reflect a federal geospatial market that is less focused on new capability acquisition and more focused on fortifying the data and software infrastructure it already has. That posture shift has direct implications for government contract strategy.
Satellite-Based Predictive Analytics Expands Into Commodity Markets
Geospatial FM’s profile of QuantAgri, a startup using satellite data to predict USDA’s monthly WASDE agricultural supply and demand reports, illustrates a market trajectory worth tracking: the commercialization of EO analytics as a financial edge tool in commodity trading. This use case, satellite-derived crop intelligence feeding into trading models, represents a premium, high-margin vertical that bypasses traditional government or enterprise procurement cycles. It also highlights a useful counterpoint to Bill Dollins’s essay this week, discussed in the Technology section, which argues that satellite data has genuine blind spots in tracking industrial infrastructure transitions. Both point to a maturing EO market in which buyers are becoming sophisticated enough to understand where satellite analytics delivers alpha and where it does not.
Notable Company Activity
Funding and M&A
- VertiGIS × 1Spatial: VertiGIS completed a £87 million take-private acquisition of 1Spatial, combining VertiGIS’s enterprise GIS application platform with 1Spatial’s geospatial data quality, governance, and management capabilities. The deal is framed around delivering AI-ready spatial data infrastructure for network operators, utilities, and government customers globally.
- Spaceflux: London-based space situational awareness company Spaceflux raised a £3.5 million extension to its seed round, bringing total funding to £9 million. The capital will fund global expansion of its space intelligence platform, which tracks objects and activity in Earth orbit for commercial and government customers.
Product Releases
- Esri, ArcGIS GeoEvent Server Deprecation: Esri announced the formal deprecation of ArcGIS GeoEvent Server, its legacy real-time event processing product. The deprecation points to Esri’s strategic migration of real-time geospatial capabilities to cloud-native and ArcGIS Velocity-based workflows. This is a meaningful architecture shift for enterprise customers running real-time IoT or sensor pipelines.
- Bentley Systems, FedRAMP Authorization: Bentley Systems achieved FedRAMP authorization for ProjectWise, its connected data environment, and OpenGround, its subsurface data management product. The authorization clears the path for U.S. federal agencies to use Bentley’s infrastructure digital twin platform in regulated cloud environments.
Partnerships
- HTX × ST Engineering, Singapore: Singapore’s Home Team Science & Technology Agency and ST Engineering announced a new space technology program targeting enhanced public safety operations. The partnership is an early indicator of Asia-Pacific government demand for integrated space-derived intelligence in domestic security applications.
Government and Policy Developments
FedGeoDay 2026 was the week’s most substantive government development. Two independent observers, Bill Dollins at geoMusings and the Project Geospatial team, both covered the event and noted that the program was organized around a thematic spine of data preservation and federal stewardship. The practical implication is clear: U.S. federal geospatial strategy is currently oriented around protecting and maintaining existing spatial data assets rather than expanding capabilities, a direct response to the fiscal and organizational pressures on civilian agencies. For vendors, this is a shift from sell-new to maintain-and-secure, with procurement conversations centering on data resilience and continuity rather than feature expansion.
Bentley Systems’ FedRAMP announcement is a complementary development. ProjectWise and OpenGround joining the FedRAMP authorized list removes a key procurement barrier for federal infrastructure agencies, particularly those managing the Biden-era infrastructure buildout assets now operating under the current administration’s scrutiny. Compliance certification is not glamorous, but in the federal market it is the precondition for revenue.
The ISPRS Congress announcement, with the XXV International Society for Photogrammetry and Remote Sensing Congress returning to Canada for the first time in decades and co-locating with the 47th Canadian Symposium on Remote Sensing, points to the continued elevation of Canada as a geospatial industry hub. GeoIgnite 2026 in Ottawa, scheduled for May 11–13, adds to this picture. For executives with North American government or academic portfolios, the Canadian geospatial market warrants closer attention this year.
Technology and Research Trends
The week’s most thought-provoking analytical piece came from Bill Dollins at geoMusings: “What Spatial Finance Cannot See From Orbit.” Using the premature retirement of a Maryland coal plant as a case study, Dollins argues that satellite imagery and EO-derived spatial finance tools systematically undercount the pace of industrial infrastructure transitions because the physical footprint of a plant does not change when its operations cease. This is a calibration argument, not a dismissal. EO data is a leading indicator in some contexts and a lagging one in others, and sophisticated buyers are increasingly capable of distinguishing between them. For the spatial finance market, this piece functions as a market maturation marker. The buyers are getting smarter.
The Earth models debate, articulated in Reimagining Geospatial’s “Autonomous Flying Cars and Geospatial Earth Models,” raises a structural architecture question that will have vendor strategy implications for the next 24 months. The author’s position that specialized vertical models are more likely to prevail over a single monolithic Earth model aligns with the general direction of AI development across other domains. If correct, it suggests that geospatial AI value will accrue to domain-specific applications, such as agriculture, infrastructure, and emergency management, rather than to general-purpose foundation model providers. This has direct implications for how executives should evaluate GeoAI platform investments.
ECOSTRESS land surface temperature data is emerging as a serious tool for characterizing active wildfire behavior in near real time, a trend documented this week in EarthStuff’s coverage of a new peer-reviewed application. Separately, Spatial Source reported on a multi-sensor approach combining GIS, LiDAR, and AI for high-resolution tree cover loss monitoring. Both developments show continued momentum in applied EO analytics for environmental monitoring use cases, where government and insurance market demand is growing.
Open Source Ecosystem Signals
GDAL v3.12.4 shipped this week, a maintenance release noted by the #geoObserver feed. While not a feature release, the cadence of GDAL maintenance updates matters. GDAL underpins virtually every geospatial pipeline in production, and the continued pace of patch releases reflects healthy core maintainer activity. Organizations evaluating the health of their open-source dependencies should track GDAL maintenance velocity as a baseline indicator.
Esri’s deprecation of ArcGIS GeoEvent Server has indirect open-source implications. Organizations running real-time geospatial pipelines on GeoEvent Server that are unwilling or unable to migrate to Esri’s cloud-native replacement may look to open-source alternatives, such as Apache Kafka with spatial extensions or GeoServer’s OGC API Features real-time implementations, as migration paths. Esri’s deprecation decision creates a procurement opening that open-source stack integrators should consider.
Mapscaping’s large-scale publication this week of state-by-state public data maps, including PFAS contamination, wind turbines, EV charging stations, power plants, and storm reports, is a notable content and SEO play rather than a product announcement. It also points to growing commercial appetite for localized, authoritative public-data visualizations as a discovery and lead-generation tool. The underlying data layers are open. The differentiation is in packaging and accessibility.
Watch List
- Space Situational Awareness as a Commercial Market: Spaceflux’s £9M raise and Singapore’s HTX/ST Engineering space program both appeared in the same week. The commercial SSA market, which tracks orbital objects and activity, is attracting sustained capital and government partnership attention outside the traditional defense procurement path.
- GeoAI Vocabulary Hardening: The phrase “decision loop” appears in the Alameh interview, while “Earth models” anchors the Reimagining Geospatial piece. When independent voices begin converging on the same vocabulary, vendor positioning language often follows. Watch for these terms in product announcements over the next 60 days.
- Satellite-Derived Commodity Trading Intelligence: QuantAgri’s EO-to-WASDE prediction model represents a thin edge of a market, satellite analytics sold into commodity trading workflows, that is distinct from enterprise GIS and worth monitoring for funding activity.
- Canadian Geospatial Market Elevation: GeoIgnite 2026, scheduled for May 11–13 in Ottawa, and the ISPRS Congress announcement position Canada as an unusually active geospatial hub this cycle. Executive attention and vendor investment may follow.
- Foursquare Conversational API: Foursquare published an internal post this week on testing methodology for its conversational location API. This is a sign that production-grade natural language location interfaces may be closer to deployment than they appear in public announcements.
Top Posts of the Week
- VertiGIS acquires 1Spatial: Discover what this means for geospatial customers, products, and the industry, VertiGIS Blog. The definitive primary source on the week’s largest M&A transaction, framing the deal as an AI-readiness play for geospatial data quality at scale.
- FedGeoDay 2026: Four Talks Worth Your Attention, geoMusings by Bill Dollins. A substantive summary of FedGeoDay’s data-preservation-focused agenda and the most direct window into current U.S. federal geospatial strategy.
- From Maps to Decision Loops: Nadine Alameh on Rethinking Geospatial in the Age of AI, GoGeomatics. A pre-GeoIgnite interview articulating the “decision loop” framing for GeoAI that is gaining traction as the industry’s organizing narrative for 2026.
- What Spatial Finance Cannot See From Orbit, geoMusings by Bill Dollins. A rigorous critical analysis of EO data’s blind spots in spatial finance applications, essential reading for anyone pricing or purchasing satellite-derived analytics.
- Autonomous Flying Cars and Geospatial Earth Models, Reimagining Geospatial. A structural analysis of the monolithic-versus-specialized Earth model debate, with direct implications for how executives should evaluate geospatial AI platform bets over the next two years.
Cercana Executive Briefing is generated from 153 feeds aggregated by geofeeds.me.