Introduction
Geospatial data volumes and complexity are growing due to diverse sources, such as GPS, satellite imagery, and sensor data. Traditional geospatial processing methods face challenges, including scalability, handling various formats, and ensuring data consistency. The medallion architecture offers a layered approach to data management, improving data processing, reliability, and scalability. While the medallion architecture is often associated with specific implementation such as the Delta Lake, its concepts are applicable to other technical implementations. This post introduces the medallion architecture and discusses two workflows—traditional GIS-based and advanced cloud-native—to demonstrate how it can be applied to geospatial data processing.
Overview of the Medallion Architecture
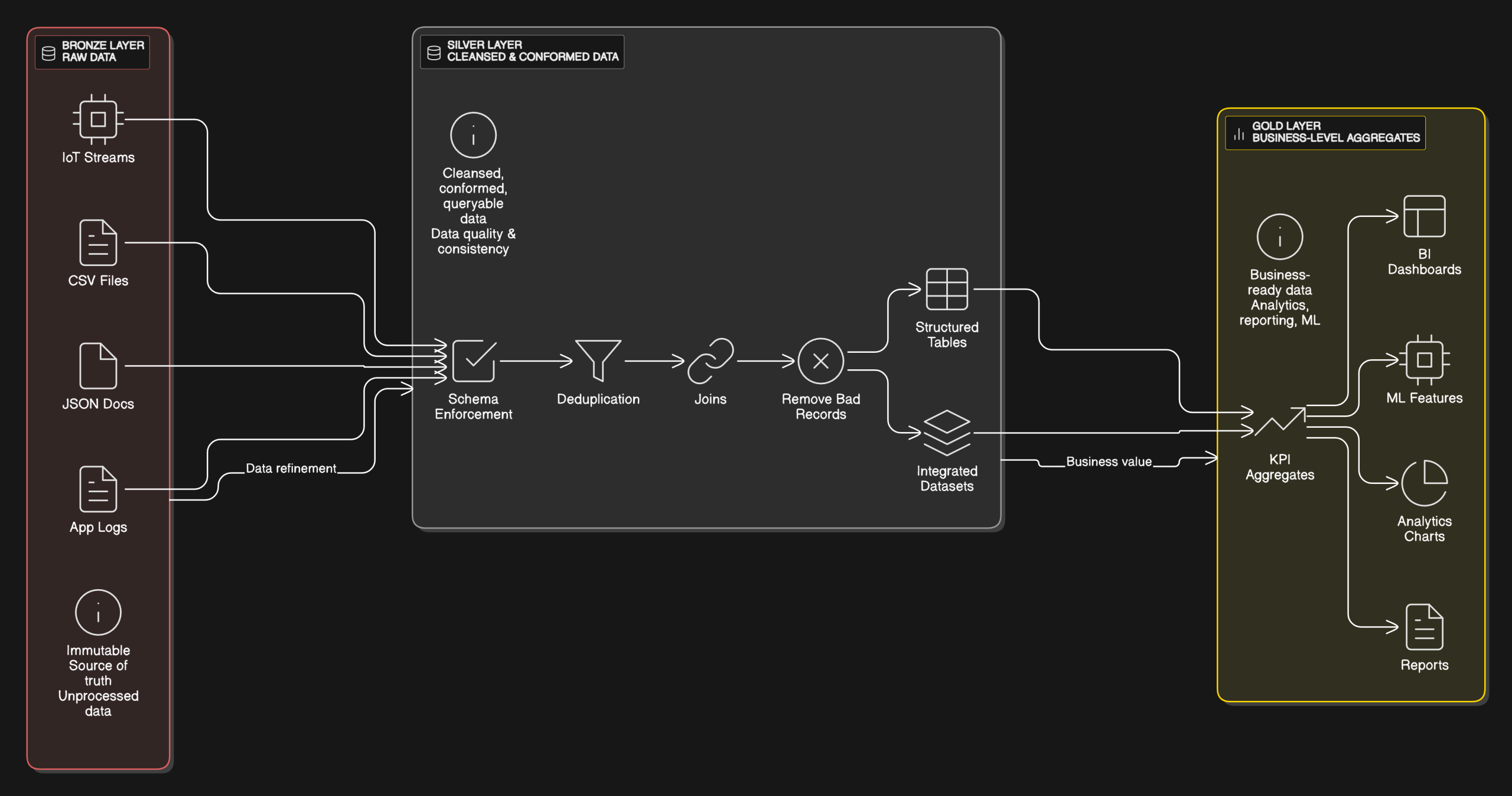
The medallion architecture was developed to address the need for incremental, layered data processing, especially in big data and analytics environments. It is composed of three layers:
- Bronze Layer: Stores raw data as-is from various sources.
- Silver Layer: Cleans and transforms data for consistency and enrichment.
- Gold Layer: Contains aggregated and optimized data ready for analysis and visualization.
The architecture is particularly useful in geospatial applications due to its ability to handle large datasets, maintain data lineage, and support both batch and real-time data processing. This structured approach ensures that data quality improves progressively, making downstream consumption more reliable and efficient.

Why Geospatial Data Architects Should Consider the Medallion Architecture
Geospatial data processing involves unique challenges, such as handling different formats (raster, vector), managing spatial operations (joins, buffers), and accommodating varying data sizes. Traditional methods struggle when scaling to large, real-time datasets or integrating data from multiple sources. The medallion architecture addresses these challenges through its layered approach. The bronze layer preserves the integrity of raw data, allowing for transformations to be traced easily. The silver layer handles transformations of the data, such as projections, spatial joins, and data enrichment. The gold layer provides ready-to-consume, performance optimized data ready for downstream systems.
Example Workflow 1: Traditional GIS-Based Workflow
For organizations that rely on established GIS tools or operate with limited cloud infrastructure, the medallion architecture provides a structured approach to data management while maintaining compatibility with traditional workflows. This method ensures efficient handling of both vector and raster data, leveraging familiar GIS technologies while optimizing data accessibility and performance.
This workflow integrates key technologies to support data ingestion, processing, and visualization. FME serves as the primary ETL tool, streamlining data movement and transformation. Object storage solutions like AWS S3 or Azure Blob Storage store raw spatial data, ensuring scalable and cost-effective management. PostGIS enables spatial analysis and processing for vector datasets. Cloud-Optimized GeoTIFFs (COGs) facilitate efficient access to large raster datasets by allowing partial file reads, reducing storage and processing overhead.
Bronze – Raw Data Ingestion
The process begins with the ingestion of raw spatial data into object storage. Vector datasets, such as Shapefiles and CSVs containing spatial attributes, are uploaded alongside raster datasets like GeoTIFFs. FME plays a crucial role in automating this ingestion, ensuring that all incoming data is systematically organized and accessible for further processing.
Silver – Data Cleaning and Processing
At this stage, vector data is loaded into PostGIS, where essential transformations take place. Operations such as spatial joins, coordinate system projections, and attribute filtering help refine the dataset for analytical use. Meanwhile, raster data undergoes optimization through conversion into COGs using FME. This transformation enhances performance by enabling GIS applications to read only the necessary portions of large imagery files, improving efficiency in spatial analysis and visualization.
Gold – Optimized Data for Analysis and Visualization
Once processed, the refined vector data in PostGIS and optimized raster datasets in COG format are made available for GIS tools. Analysts and decision-makers can interact with the data using platforms such as QGIS, Tableau, or Geoserver. These tools provide the necessary visualization and analytical capabilities, allowing users to generate maps, conduct spatial analyses, and derive actionable insights.
This traditional GIS-based implementation of medallion architecture offers several advantages. It leverages established GIS tools and workflows, minimizing the need for extensive retraining or infrastructure changes. It is optimized for traditional environments yet still provides the flexibility to integrate with hybrid or cloud-based analytics platforms. Additionally, it enhances data accessibility and performance, ensuring that spatial datasets remain efficient and manageable for analysis and visualization.
By adopting this workflow, organizations can modernize their spatial data management practices while maintaining compatibility with familiar GIS tools, resulting in a seamless transition toward more structured and optimized data handling.
Example Workflow 2: Advanced Cloud-Native Workflow
For organizations managing large-scale spatial datasets and requiring high-performance processing in cloud environments, a cloud-native approach to medallion architecture provides scalability, efficiency, and advanced analytics capabilities. By leveraging distributed computing and modern storage solutions, this workflow enables seamless processing of vector and raster data while maintaining cost efficiency and performance.
This workflow is powered by cutting-edge cloud-native technologies that optimize storage, processing, and version control.
Object Storage solutions such as AWS S3, Google Cloud Storage, or Azure Blob Storage serve as the foundation for storing raw geospatial data, ensuring scalable and cost-effective data management. Apache Spark with Apache Sedona enables large-scale spatial data processing, leveraging distributed computing to handle complex spatial joins, transformations, and aggregations. Delta Lake provides structured data management, supporting versioning and ACID transactions to ensure data integrity throughout processing. RasterFrames or Rasterio facilitate raster data transformations, including operations like mosaicking, resampling, and reprojection, while optimizing data storage and retrieval.
Bronze – Raw Data Ingestion
The workflow begins by ingesting raw spatial data into object storage. This includes vector data such as GPS logs in CSV format and raster data like satellite imagery stored as GeoTIFFs. By leveraging cloud-based storage solutions, organizations can manage and access massive datasets without traditional on-premises limitations.
Silver – Data Processing and Transformation
At this stage, vector data undergoes large-scale processing using Spark with Sedona. Distributed spatial operations such as filtering, joins, and projections enable efficient refinement of large datasets. Meanwhile, raster data is transformed using RasterFrames or Rasterio, which facilitate operations like mosaicking, resampling, and metadata extraction. These tools ensure that raster datasets are optimized for both analytical workloads and visualization purposes.
Gold – Optimized Data for Analysis and Visualization
Once processed, vector data is stored in Delta Lake, where it benefits from structured storage, versioning, and enhanced querying capabilities. This ensures that analysts can access well-maintained datasets with full historical tracking. Optimized raster data is converted into Cloud-Optimized GeoTIFFs, allowing efficient cloud-based visualization and integration with GIS tools. These refined datasets can then be used in cloud analytics environments or GIS platforms for advanced spatial analysis and decision-making.
This cloud-native implementation of medallion architecture provides several advantages for large-scale spatial data workflows. It features high scalability, enabling efficient processing of vast datasets without the constraints of traditional infrastructure, parallelized data transformations, significantly reducing processing time through distributed computing frameworks, and cloud-native optimizations, ensuring seamless integration with advanced analytics platforms, storage solutions, and visualization tools.
By adopting this approach, organizations can harness the power of cloud computing to manage, analyze, and visualize geospatial data at an unprecedented scale, improving both efficiency and insight generation.
Comparing the Two Workflows
| Aspect | Traditional Workflow (FME + PostGIS) | Advanced Workflow (Spark + Delta Lake) |
| Scalability | Suitable for small to medium workloads | Ideal for large-scale datasets |
| Technologies | FME, PostGIS, COGs, file system or object storage | Spark, Sedona, Delta Lake, RasterFrames, object storage |
| Processing Method | Sequential or batch processing | Parallel and distributed processing |
| Performance | Limited by local infrastructure or on-premise servers | Optimized for cloud-native and distributed environments |
| Use Cases | Small teams, traditional GIS setups, hybrid cloud setups | Large organizations, big data environments |
Key Takeaways
The medallion architecture offers much needed flexibility and scalability for geospatial data processing. It meshes well with traditional workflows using FME and PostGIS, which is effective for organizations with established GIS infrastructure. Additionally, it can be used in cloud-native workflows using Apache Spark and Delta Lake to provide scalability for large-scale processing. Both of these workflows can be adapted depending on the organization’s technological maturity and requirements.
Conclusion
Medallion architecture provides a structured, scalable approach to geospatial data management, ensuring better data quality and streamlined processing. Whether using a traditional GIS-based workflow or an advanced cloud-native approach, this framework helps organizations refine raw spatial data into high-value insights. By assessing their infrastructure and data needs, teams can adopt the workflow that best aligns with their goals, optimizing efficiency and unlocking the full potential of their geospatial data.